| CVPR 2023 | 您所在的位置:网站首页 › transformer网络 图像 › CVPR 2023 |
CVPR 2023
论文:https://arxiv.org/pdf/2303.09998.pdf代码:https://github.com/MediaBrain-SJTU/TBP-Former作者单位:上海交通大学 University of Southern California 上海人工智能实验室 论文思路: 论文思路:以视觉为中心的联合感知与预测(PnP)已成为自主驾驶研究的新趋势。它从原始的RGB图像预测交通参与者在周围环境的未来状态。然而,由于不可避免的几何畸变,如何同步在多个相机视图和时间戳上获得的特征并进一步利用这些时空特征仍然是一个关键的挑战。为了解决这个问题,本文提出一种时间鸟瞰图金字塔transformer(temporal bird’s-eye-view pyramid transformer)(TBPFormer)为视觉为中心的PnP,其中包括两个新的设计。首先,本文提出的一种位姿同步(pose-synchronized)的BEV编码器,将任意时刻任意相机姿态的原始图像输入映射到一个共享的同步的BEV空间,以获得更好的时空同步。其次,引入时空金字塔transformer综合提取多尺度BEV特征,并在空间先验的支持下预测未来BEV状态。在nuScenes数据集上的大量实验表明,本文提出的框架总体上优于所有基于视觉的SOTA预测方法。 作者:汽车人 | 自动驾驶之心->:【3D目标检测交流群】点击关注@自动驾驶之心,第一时间看到最前沿与价值的CV/自动驾驶/AI类工作~强烈推荐!自动驾驶与AI学习社区:欢迎加入国内首个自动驾驶开发者社区!这里有最全面有效的自动驾驶与AI学习路线(感知/定位/融合)和自动驾驶与AI公司内推机会! 求职社群来了!面向自动驾驶与AI相关的算法/开发求职,面试题目/面经/日常吐槽应有尽有! 主要贡献:为了解决时序图像序列到同步BEV空间的映射失真问题,本文提出一种基于跨视图注意力机制的位姿同步(pose-synchronized) BEV编码器(PoseSync BEV Encoder)来提取高质量的时序BEV特征。 本文提出一种新颖的时空金字塔Transformer(STPT)来从连续的BEV地图中提取多尺度的时空特征,并根据与空间先验相结合的详尽的未来查询来预测未来的BEV状态。 总之,本文提出TBP-Former,一个基于视觉的自动驾驶联合感知和预测框架。TBP-Former在nuScenes[2]数据集上实现了最先进的基于视觉的预测任务。大量的实验表明,PoseSync BEV编码器和STPT编码器都对性能有很大的贡献。由于该框架的解耦特性,这两个提出的模块可以很容易地在任何基于视觉的BEV预测框架中作为备选模块使用。 网络设计: 图1。基于视觉的感知和预测的两个主要挑战是(a)如何避免失真和缺陷时,聚集的特征跨越时间和相机视图;(b)如何实现时空特征学习进行预测。本文的位姿同步(Pose-Synchronized)BEV编码器可以精确地将视觉特征映射到同步的BEV空间中,时空金字塔Transformer可以在多个尺度上提取特征。 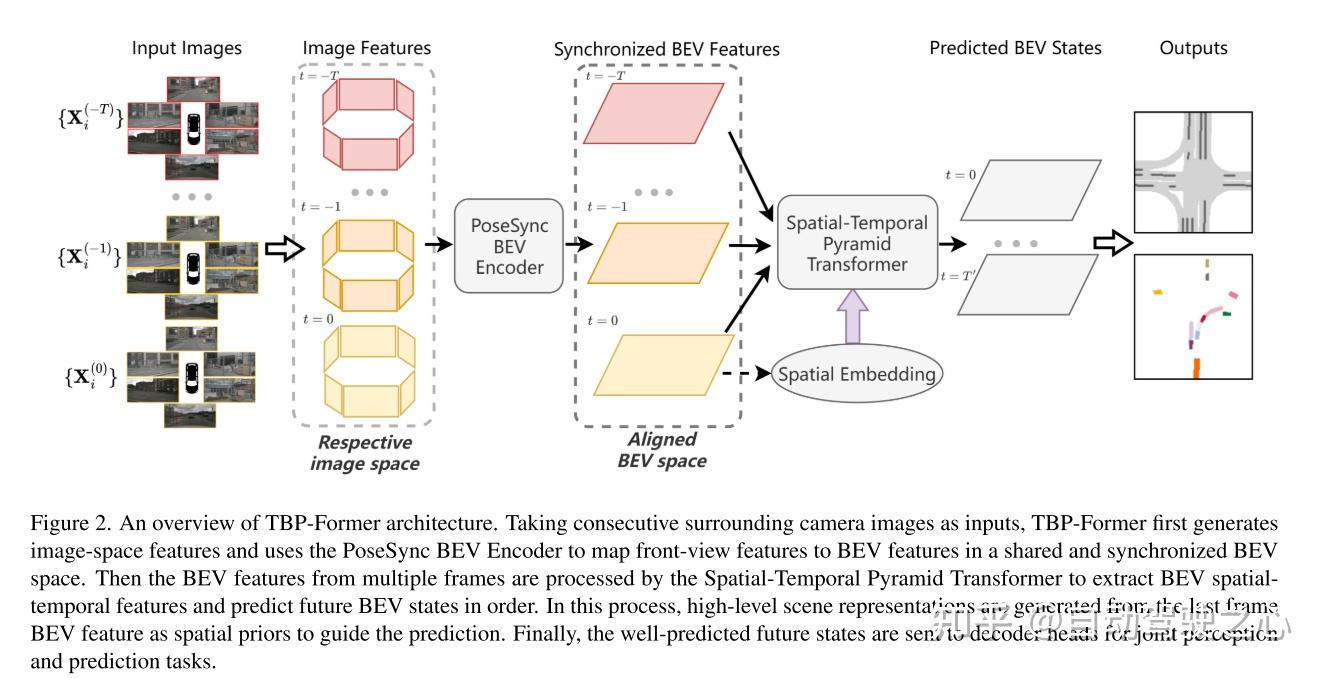 图2。TBP-Former体系结构概述。以周围连续的摄像机图像作为输入,TBP-Former首先生成图像空间特征,并使用PoseSync BEV编码器在共享和同步的BEV空间中将前视图特征映射到BEV特征。然后利用时空金字塔Transformer对多帧图像中的BEV特征进行处理,提取出BEV的时空特征,并对未来的BEV状态进行排序预测。在此过程中,将最后一帧BEV特征作为空间先验生成高级场景表示来指导预测。最后,预测好的未来状态被发送到解码器头进行联合感知和预测任务。 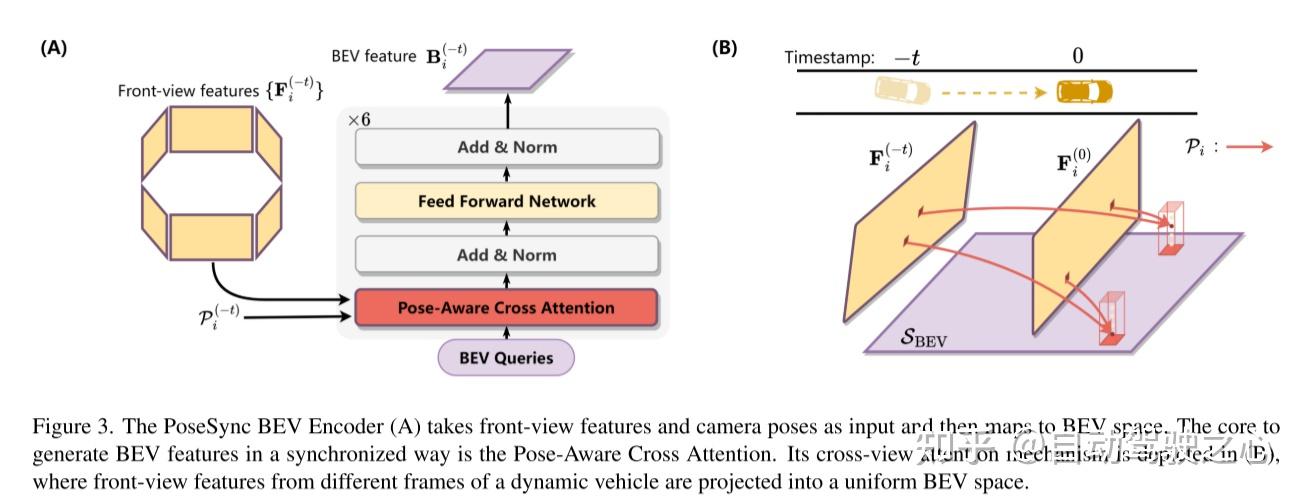 图3。PoseSync BEV编码器(A)采用前视图特征和摄像机姿态作为输入,然后映射到BEV空间。以同步方式生成BEV特征的核心是Pose-Aware Cross Attention。其跨视图注意力机制如(B)所示,其中来自动态车辆不同框架的前视图特征被投影到统一的BEV空间中。  图4。时空金字塔Transformer(STPT)的网络结构。每个编码器层包含一个可选的卷积块用于下行采样和SwinTransformer块,而每个解码器层包含一个SwinTransformer块和一个反卷积块用于上行采样。在解码过程中,本文预先定义了一组表示未来BEV状态的查询,并从编码器中查询特征。 实验结果:     0. 自动驾驶感知/定位/融合与规划全系列课程!自动驾驶感知:YOLOv3~YOLOv8/YOLOX/PPYOLO系列全栈学习教程 自动驾驶感知:国内首个BEV感知全栈学习教程(纯视觉+多传感器融合方案)1. 自动驾驶之心—3D目标检测交流群 0. 自动驾驶感知/定位/融合与规划全系列课程!自动驾驶感知:YOLOv3~YOLOv8/YOLOX/PPYOLO系列全栈学习教程 自动驾驶感知:国内首个BEV感知全栈学习教程(纯视觉+多传感器融合方案)1. 自动驾驶之心—3D目标检测交流群建了自动驾驶之心3D目标检测交流群!想要进交流群的同学,可以直接加微信号:AIDriver001。加的时候备注一下:3D目标检测+学校/公司+昵称,即可。然后就可以拉你进群了。 2. 往期回顾自动驾驶之心 | CVPR 2023 | SimpleNet:一个简单的图像异常检测和定位网络 自动驾驶之心 | CVPR 2023 | 多视图3D目标检测中的viewpoint equivariance 自动驾驶之心 | CVPR 2023 | 协同感知在真实世界就不能打了?世界首款V2V4Real告诉你很能打! 自动驾驶之心 | CVPR'23论文解读 | 多模态/3D检测/BEV/跟踪/点云等多个方向! 自动驾驶之心 | ICRA 2023 | 最新激光雷达-相机联合内外参标定,一步到位! 自动驾驶之心 | 2023最新综述!自动驾驶的运动规划:现状与展望全面回顾(传统/端到端/强化学习) 自动驾驶之心 | nuScenes SOTA!SurroundOcc:面向自动驾驶的纯视觉3D占据预测网络(清华&天大) 自动驾驶之心 | CVPR2023 | 让自动驾驶一骑绝尘!BEV-LaneDet:暴涨十个点,单目3D车道线新SOTA! 自动驾驶之心 | 最新SOTA!LAformer:具有车道感知场景约束的自动驾驶轨迹预测 自动驾驶之心 | ICRA 2023最新!自动驾驶传感器高效部署新方法! 自动驾驶之心 | CVPR2023 | 用于多模态3D目标检测的虚拟稀疏卷积(KITTI SOTA) |
【本文地址】